



根据GitHub开源项目公开的信息,ChatGLM-6B完整版本需要13GB显存做推理,但是INT4量化版本只需要6GB显存即可运行,因此对于个人本地部署来说十分友好。遗憾的是,官方的文档中缺少了一些内容导致大家本地部署会有很多问题,本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。
-
安装前说明 -
部署前安装环境 -
1、下载官方代码,安装Python依赖的库 -
2、下载INT4量化后的预训练结果文件
-
-
Windows+GPU部署方案 -
1、Windows+GPU方案的必备条件 -
2、运行部署GPU版本的INT4量化的ChatGLM-6B模型
-
-
Windows+CPU部署方案 -
1、Windows+CPU方案的必备条件 -
2、运行部署CPU版本的INT4量化的ChatGLM-6B模型
-
-
总结
安装前说明
部署前安装环境
1、下载官方代码,安装Python依赖的库

pip install -r requirements.txt
使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
AttributeError:'Logger'object has no attribute "'warning_once'"
2、下载INT4量化后的预训练结果文件

D:\\data\\llm\\chatglm-6b-int4Windows+GPU部署方案
1、Windows+GPU方案的必备条件
import torch
print(torch.cuda.is_available())

模型量化会带来一定的性能损失,经过测试,ChatGLM-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
2、运行部署GPU版本的INT4量化的ChatGLM-6B模型
from transformers importAutoTokenizer,AutoModel
tokenizer =AutoTokenizer.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="")
model =AutoModel.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="").half().cuda()
model = model.eval()
response, history = model.chat(tokenizer,"你好", history=[])
print(response)
D:\\data\\llm\\chatglm-6b-int4写法,即\\,不能写成D:/data/llm/chatglm-6b-int4。否则可能会出现如下错误:-
OSError:[WinError123]文件名、目录名或卷标语法不正确。:'C:\\Users\\DataLearner\\.cache\\huggingface\\modules\\transformers_modules\\D:'
revision=""参数,主要是规避如下告警:Explicitly passing a revision is encouraged when loading a configuration with custom code to ensureno malicious code has been contributed in a newer revision.

Windows+CPU部署方案
1、Windows+CPU方案的必备条件
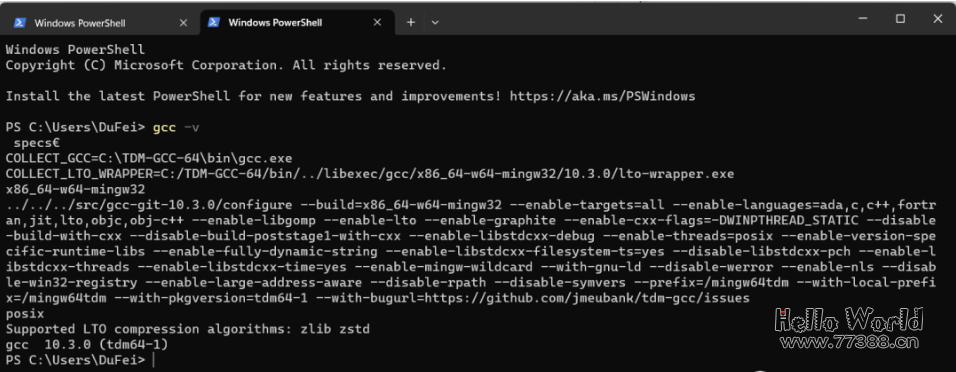
quantization_kernels.c和quantization_kernels_parallel.c这两个文件。如果大家在运行中遇到了如下错误提示:No compiled kernel found.
Compiling kernels : C:\Users\DuFei\.cache\huggingface\modules\transformers_modules\chatglm-6b-int4\quantization_kernels_parallel.c
Compiling gcc -O3 -fPIC -pthread -fopenmp -std=c99 C:\Users\DuFei\.cache\huggingface\modules\transformers_modules\chatglm-6b-int4\quantization_kernels_parallel.c -shared -o C:\Users\DuFei\.cache\huggingface\modules\transformers_modules\chatglm-6b-int4\quantization_kernels_parallel.so
Kernels compiled : C:\Users\DuFei\.cache\huggingface\modules\transformers_modules\chatglm-6b-int4\quantization_kernels_parallel.so
Cannot load cpu kernel, don't use quantized model on cpu.
Using quantization cache
Applying quantization to glm layers
D:\\data\\llm\\chatglm-6b-int4本地目录下进入cmd,运行如下两个编译命令:gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels.c -shared -o quantization_kernels.so
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels_parallel.c -shared -o quantization_kernels_parallel.so

D:\\data\\llm\\chatglm-6b-int4目录下看到下面两个新的文件:quantization_kernels_parallel.so和quantization_kernels.so。说明编译成功,后面我们手动载入即可。2、运行部署CPU版本的INT4量化的ChatGLM-6B模型
from transformers importAutoTokenizer,AutoModel
tokenizer =AutoTokenizer.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="")
model =AutoModel.from_pretrained("D:\\data\\llm\\chatglm-6b-int4",trust_remote_code=True, revision="").float()
model = model.eval()
response, history = model.chat(tokenizer,"你好", history=[])
print(response)
float()有差异:model =AutoModel.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="").float()
.half().cuda(),而这里是float()。-
AttributeError:'NoneType'object has no attribute 'int4WeightExtractionFloat'
model = model.quantize(bits=4, kernel_file="D:\\data\\llm\\chatglm-6b-int4\\quantization_kernels.so")一行手动加载的内容。
总结
ChatGLM-6B在DataLearner官方的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B
免责说明
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。



我的未来再美,没有你参与,总是显得空洞乏味。
你不需要任何自私的手段就可以留住我,因为我是你的。
不错啊