



随着LLM大语言模型兴起,各种LLM应用层出不穷,使用在线ChatGPT当然性能最强,但存在数据泄漏的担忧。
正好前不久有朋友问起,是否有本地的chatPDF项目?周末花时间研究了下,发现localGPT这个项目非常不错,已累积8.5K星星。
既然是基于本地,限于硬件性能,只能跑一些"小"模型,效果肯定要比 ChatGPT 差不少。但亮点是私密,应付一些简单的需求也是可以的。
localGPT 从 privateGPT上得来灵感,更优的是,他默认使用了GPU 进行推理,速度更快。并且很方便切换模型,以及支持API访问。
localGPT使用了LangChain, Chroma, SentenceTransformers和AutoGPTQ进行构建。
创建环境
使用python3.9,其他更高版本也可以,只是要注意,cuda, pytorch, python, torchvision 要配套对应。
conda create -n localGPT python=3.9
activate localGPT
pip install d:pylibtorch-2.0.0+cu117-cp39-cp39-win_amd64.whl
pip install d:pylibtorchvision-0.15.0+cu117-cp39-cp39-win_amd64.whl
cd d:aiworkflow
git clone https://github.com/PromtEngineer/localGPT.git
cd localGPT
pip install -r requirements.txt如果使用GPU进行推理,则安装 AutoGPTQ。
cd ..
git clone https://github.com/PanQiWei/AutoGPTQ.git
cd AutoGPTQ
git checkout v0.2.2
pip install .
设定模型目录
如果不设置,则默认到 C 盘下
set TRANSFORMERS_CACHE=D:modelslocalGPT
模型下载、推埋
推理阶段,会自动从抱抱脸下载所需模型(所需空间 3.62GB):

文档分析
将待分析的文档,放到一个目录内,我丢了一份gd32的 datasheet 给他分析。文档目录就建在工程目录之下,然后再建一个存储向量数据库的目录 gd32db。
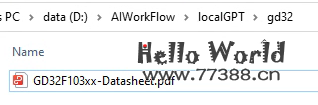
修改 constants.py
SOURCE_DIRECTORY = f"{ROOT_DIRECTORY}/gd32"
PERSIST_DIRECTORY = f"{ROOT_DIRECTORY}/gd32db"文档格式支持 .txt, .pdf, .csv, 和 .xlsx。如果你是其他格式的文档,则需先转换为上述格式。
进行文档分析:
cd d:aiworkflowlocalGPT
python ingest.py
稍等片刻,程序运行完会自动退出,此时在 gd32db 目录下,可以看到 chroma 数据库文件

推理
python run_localGPT.py
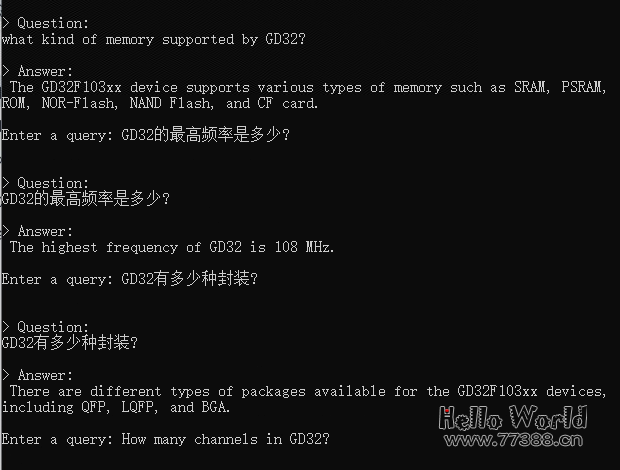
提了几个简单问题,localGPT都回答正确。
localGPT使用了AutoGPT项目来管理模型,所以能轻易修改模型名称,以切换不同的模型来推理:

如下修改,重新启动,就能直接下载13b模型,并用于新的推理:
model_id = "TheBloke/Nous-Hermes-13B-GPTQ"
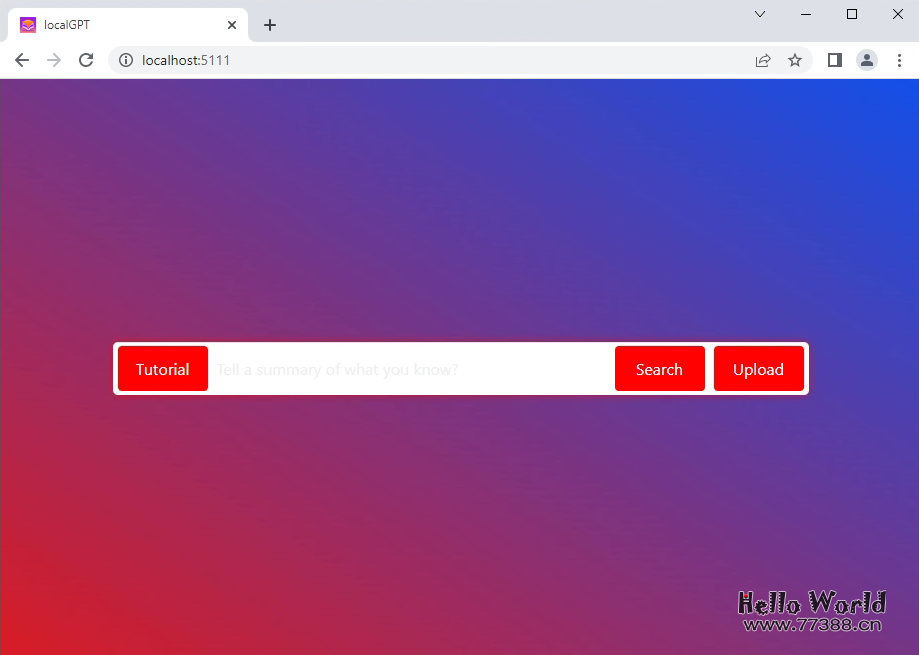
model_basename = "nous-hermes-13b-GPTQ-4bit-128g.no-act.order"提供了简洁的webUI访问方式,并且在回答中,显示了答案的引用来源:
项目亮点:
-
本地部署,隐私性强 -
支持多种文件格式: .txt, .pdf, .csv, 和 .xlsx -
默认GPU推理,推理速度快 -
使用AutoGPT管理模型,切换模型很方便 -
提供API/WebUI方问,能方便与其他工具集成,也方便普通用户使用
下载地址:


