



微信机器人是什么?
通过微信公众平台提供的接口通过一定的数据逻辑和数据库实现在微信平台上的智能对话
微信机器人指通过微信公众平台提供的接口通过一定的数据逻辑和数据库实现在微信平台上的智能对话。
简单的机器人如天气查询、美食查询等,高级点如陪聊机器人、对话机器人、智能查询等。
部署微信机器人方案:
这里讲到的方案有2种,适合不同的人群,按照自己的需求决定采用哪种方案来部署;
第一种方案:
宝塔部署(Docker)无基础的推荐次方案;
第二种方案:
服务器命令部署,有编程基础的推荐次方案;
部署微信聊天机器人的条件:
1、云服务器(本地部署无需服务器,不推荐无编程基础的使用本地部署方案);
2、Openai KEY(这个是必须条件,无K的可以参照我们的教程,自己申请一个);
开始教程:
方案一:宝塔部署
准备服务器,有服务器的可跳过此处;
买一个配置最低的服务器就可以了,每月大约30块钱;
推荐腾讯云购买,大厂的稳定,关键还便宜,地址:https://curl.qcloud.com/yeodm7nV
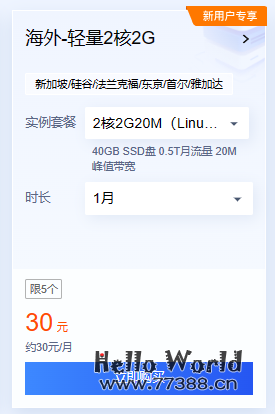
推荐使用海外的服务器,可以不用代理,直接使用OpenAI官方API的接口网址;
使用应用模板,宝塔Linux面板8.0.1腾讯云专享版,宝塔操作简单,非常适合新手小白,地区选欧洲和美洲,随便选一个海外地区都可以
如果你有自己的国内服务器,不想再开销一笔,也可以使用本站的OpenAi API代理地址:
https://api-openai.bcloud.store/要拿到宝塔用户名和密码,我们需要登录一下服务器,网站右上角的站内信有服务器的账号密码和ip,也有登录链接,点击可以直接登录。也可以在宝塔的概要页面点登录按钮。
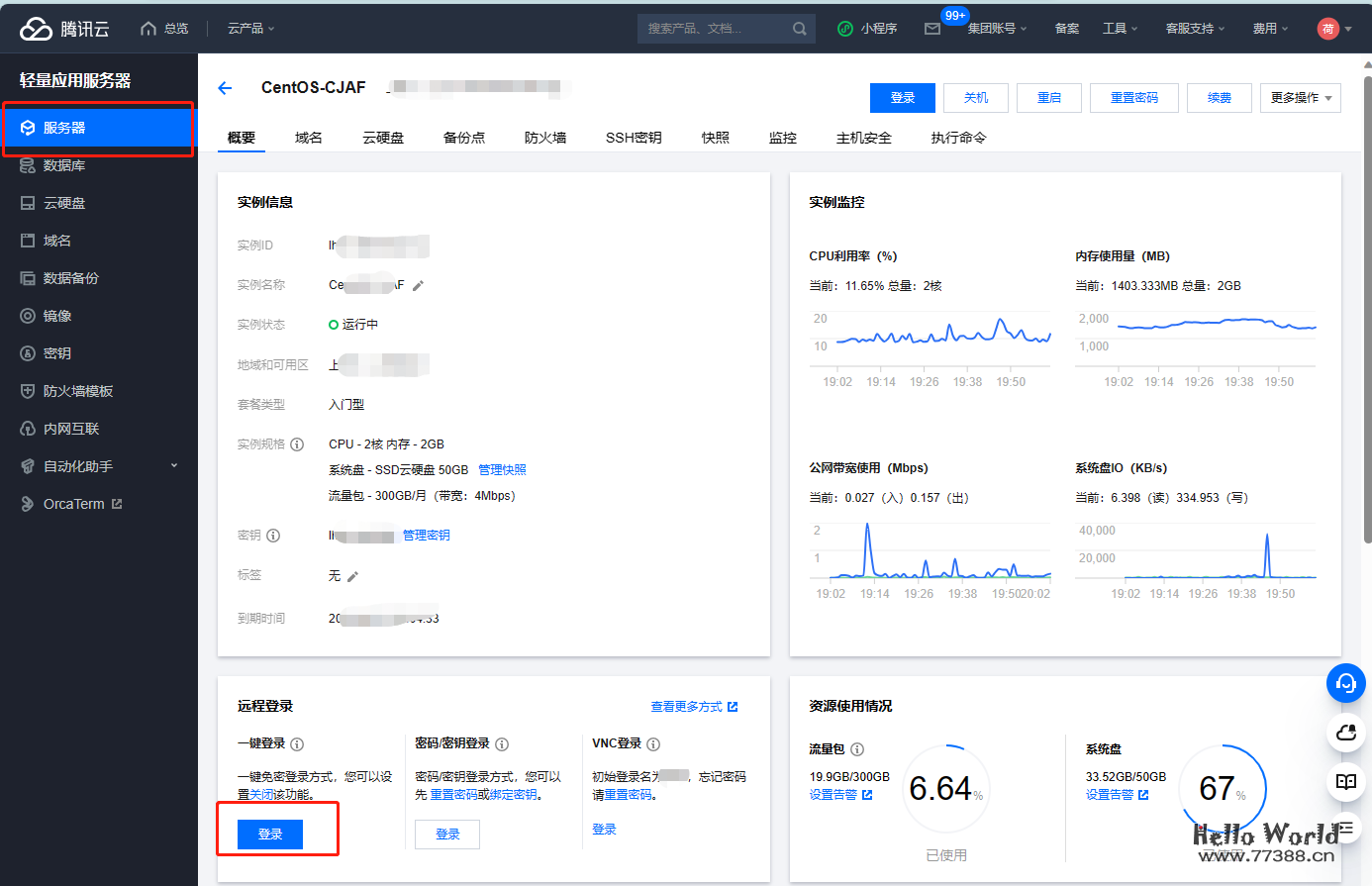
登录成功后,我们输入以下命令就可以拿到宝塔的管理地址及账号密码:
sudo /etc/init.d/bt default
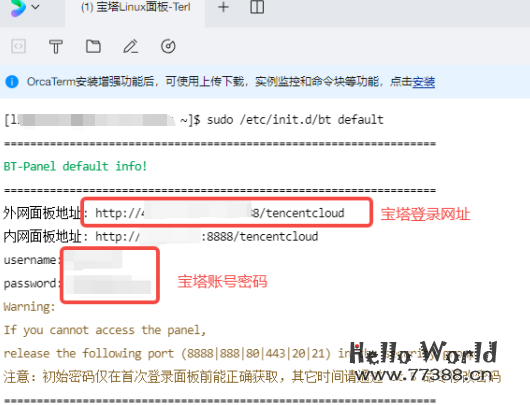
然后浏览器地址栏输入上面的管理地址(外网),输入账号密码登录,安装Docker:
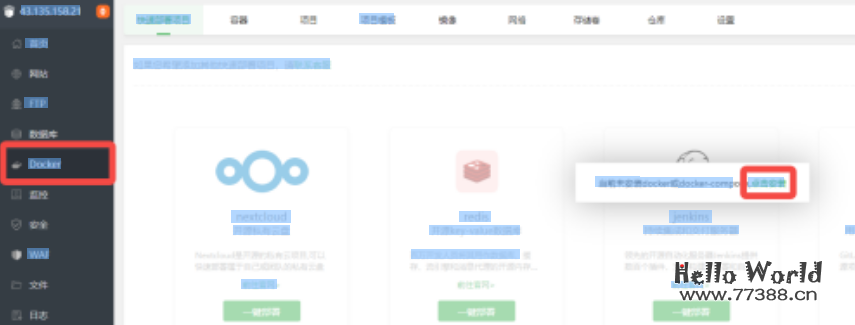
(安装完成的请跳过此步骤)如果此时点击顶部的容器、项目、项目模板还是显示第一张照片那样(显示未安装),那则需要使用命令行安装docker,如下图:
左侧找到终端,输入
/bin/bash /www/server/panel/install/install_soft.sh 0 install docker_install
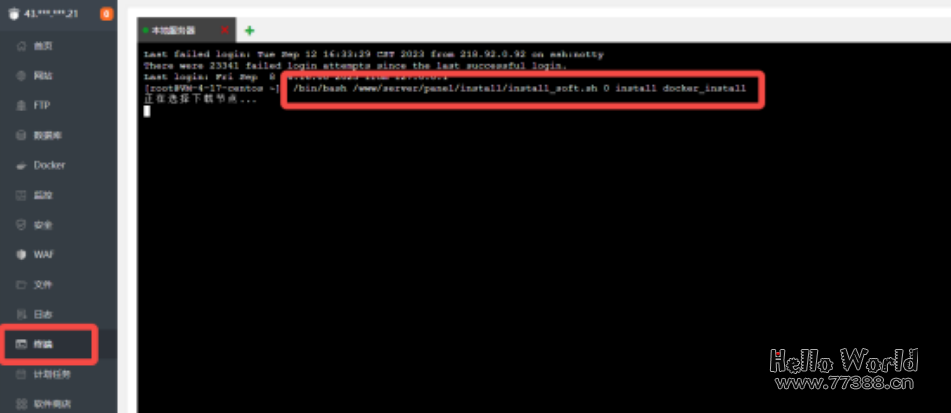
等待安装完成,再次打开docker菜单查看是否还报错。不报错则是成功安装
下载配置docker文件
随便一个浏览器输入以下网址,即可下载docker-compose.yml文件:
https://open-1317903499.cos.ap-guangzhou.myqcloud.com/docker-compose.yml
右击用记事本打开可以看到以下内容
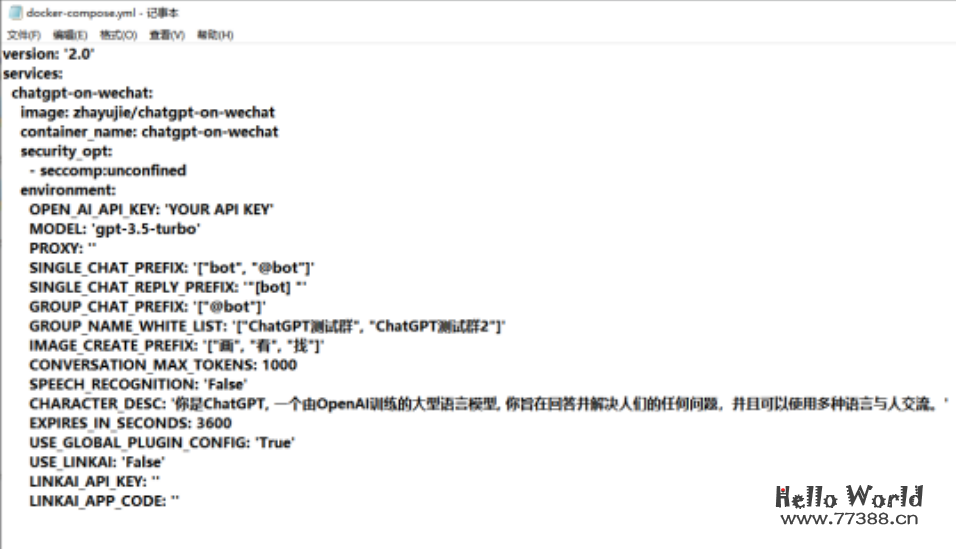
满足自定义需要,我们可以进行一些简单的修改:
1、修改OPEN_AI_API_KEY的值为之前准备的openai key
2、如果我们需要所有的群都触发机器人,则GROUP_NAME_WHITE_LIST:后面要改成'["ALL_GROUP"]'
比如你在群聊时每次加关键词ai,机器人就可以自动触发,则配置GROUP_CHAT_PREFIX: '["ai"]'
3、更多参数配置请参考下面链接:
# encoding:utf-8
import json
import logging
import os
import pickle
from common.log import logger
# 将所有可用的配置项写在字典里, 请使用小写字母
# 此处的配置值无实际意义,程序不会读取此处的配置,仅用于提示格式,请将配置加入到config.json中
available_setting = {
# openai api配置
"open_ai_api_key": "", # openai api key
# openai apibase,当use_azure_chatgpt为true时,需要设置对应的api base
"open_ai_api_base": "https://api.openai.com/v1",
"proxy": "", # openai使用的代理
# chatgpt模型, 当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
"model": "gpt-3.5-turbo", # 还支持 gpt-3.5-turbo-16k, gpt-4, wenxin, xunfei
"use_azure_chatgpt": False, # 是否使用azure的chatgpt
"azure_deployment_id": "", # azure 模型部署名称
"azure_api_version": "", # azure api版本
# Bot触发配置
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"single_chat_reply_suffix": "", # 私聊时自动回复的后缀,\n 可以换行
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"group_chat_reply_prefix": "", # 群聊时自动回复的前缀
"group_chat_reply_suffix": "", # 群聊时自动回复的后缀,\n 可以换行
"group_chat_keyword": [], # 群聊时包含该关键词则会触发机器人回复
"group_at_off": False, # 是否关闭群聊时@bot的触发
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_name_keyword_white_list": [], # 开启自动回复的群名称关键词列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"trigger_by_self": False, # 是否允许机器人触发
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"concurrency_in_session": 1, # 同一会话最多有多少条消息在处理中,大于1可能乱序
"image_create_size": "256x256", # 图片大小,可选有 256x256, 512x512, 1024x1024
# chatgpt会话参数
"expires_in_seconds": 3600, # 无操作会话的过期时间
# 人格描述
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。",
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
# chatgpt限流配置
"rate_limit_chatgpt": 20, # chatgpt的调用频率限制
"rate_limit_dalle": 50, # openai dalle的调用频率限制
# chatgpt api参数 参考https://platform.openai.com/docs/api-reference/chat/create
"temperature": 0.9,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"request_timeout": 60, # chatgpt请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": 120, # chatgpt重试超时时间,在这个时间内,将会自动重试
# Baidu 文心一言参数
"baidu_wenxin_model": "eb-instant", # 默认使用ERNIE-Bot-turbo模型
"baidu_wenxin_api_key": "", # Baidu api key
"baidu_wenxin_secret_key": "", # Baidu secret key
# 讯飞星火API
"xunfei_app_id": "", # 讯飞应用ID
"xunfei_api_key": "", # 讯飞 API key
"xunfei_api_secret": "", # 讯飞 API secret
# claude 配置
"claude_api_cookie": "",
"claude_uuid": "",
# wework的通用配置
"wework_smart": True, # 配置wework是否使用已登录的企业微信,False为多开
# 语音设置
"speech_recognition": False, # 是否开启语音识别
"group_speech_recognition": False, # 是否开启群组语音识别
"voice_reply_voice": False, # 是否使用语音回复语音,需要设置对应语音合成引擎的api key
"always_reply_voice": False, # 是否一直使用语音回复
"voice_to_text": "openai", # 语音识别引擎,支持openai,baidu,google,azure
"text_to_voice": "baidu", # 语音合成引擎,支持baidu,google,pytts(offline),azure,elevenlabs
# baidu 语音api配置, 使用百度语音识别和语音合成时需要
"baidu_app_id": "",
"baidu_api_key": "",
"baidu_secret_key": "",
# 1536普通话(支持简单的英文识别) 1737英语 1637粤语 1837四川话 1936普通话远场
"baidu_dev_pid": "1536",
# azure 语音api配置, 使用azure语音识别和语音合成时需要
"azure_voice_api_key": "",
"azure_voice_region": "japaneast",
# elevenlabs 语音api配置
"xi_api_key": "", #获取ap的方法可以参考https://docs.elevenlabs.io/api-reference/quick-start/authentication
"xi_voice_id": "", #ElevenLabs提供了9种英式、美式等英语发音id,分别是“Adam/Antoni/Arnold/Bella/Domi/Elli/Josh/Rachel/Sam”
# 服务时间限制,目前支持itchat
"chat_time_module": False, # 是否开启服务时间限制
"chat_start_time": "00:00", # 服务开始时间
"chat_stop_time": "24:00", # 服务结束时间
# 翻译api
"translate": "baidu", # 翻译api,支持baidu
# baidu翻译api的配置
"baidu_translate_app_id": "", # 百度翻译api的appid
"baidu_translate_app_key": "", # 百度翻译api的秘钥
# itchat的配置
"hot_reload": False, # 是否开启热重载
# wechaty的配置
"wechaty_puppet_service_token": "", # wechaty的token
# wechatmp的配置
"wechatmp_token": "", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "", # 微信公众平台的appID
"wechatmp_app_secret": "", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
# wechatcom的通用配置
"wechatcom_corp_id": "", # 企业微信公司的corpID
# wechatcomapp的配置
"wechatcomapp_token": "", # 企业微信app的token
"wechatcomapp_port": 9898, # 企业微信app的服务端口,不需要端口转发
"wechatcomapp_secret": "", # 企业微信app的secret
"wechatcomapp_agent_id": "", # 企业微信app的agent_id
"wechatcomapp_aes_key": "", # 企业微信app的aes_key
# chatgpt指令自定义触发词
"clear_memory_commands": ["#清除记忆"], # 重置会话指令,必须以#开头
# channel配置
"channel_type": "wx", # 通道类型,支持:{wx,wxy,terminal,wechatmp,wechatmp_service,wechatcom_app}
"subscribe_msg": "", # 订阅消息, 支持: wechatmp, wechatmp_service, wechatcom_app
"debug": False, # 是否开启debug模式,开启后会打印更多日志
"appdata_dir": "", # 数据目录
# 插件配置
"plugin_trigger_prefix": "$", # 规范插件提供聊天相关指令的前缀,建议不要和管理员指令前缀"#"冲突
# 是否使用全局插件配置
"use_global_plugin_config": False,
# 知识库平台配置
"use_linkai": False,
"linkai_api_key": "",
"linkai_app_code": "",
"linkai_api_base": "https://api.link-ai.chat", # linkAI服务地址,若国内无法访问或延迟较高可改为 https://api-openai.bcloud.store
}
class Config(dict):
def __init__(self, d=None):
super().__init__()
if d is None:
d = {}
for k, v in d.items():
self[k] = v
# user_datas: 用户数据,key为用户名,value为用户数据,也是dict
self.user_datas = {}
def __getitem__(self, key):
if key not in available_setting:
raise Exception("key {} not in available_setting".format(key))
return super().__getitem__(key)
def __setitem__(self, key, value):
if key not in available_setting:
raise Exception("key {} not in available_setting".format(key))
return super().__setitem__(key, value)
def get(self, key, default=None):
try:
return self[key]
except KeyError as e:
return default
except Exception as e:
raise e
# Make sure to return a dictionary to ensure atomic
def get_user_data(self, user) -> dict:
if self.user_datas.get(user) is None:
self.user_datas[user] = {}
return self.user_datas[user]
def load_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "rb") as f:
self.user_datas = pickle.load(f)
logger.info("[Config] User datas loaded.")
except FileNotFoundError as e:
logger.info("[Config] User datas file not found, ignore.")
except Exception as e:
logger.info("[Config] User datas error: {}".format(e))
self.user_datas = {}
def save_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "wb") as f:
pickle.dump(self.user_datas, f)
logger.info("[Config] User datas saved.")
except Exception as e:
logger.info("[Config] User datas error: {}".format(e))
config = Config()
def load_config():
global config
config_path = "./config.json"
if not os.path.exists(config_path):
logger.info("配置文件不存在,将使用config-template.json模板")
config_path = "./config-template.json"
config_str = read_file(config_path)
logger.debug("[INIT] config str: {}".format(config_str))
# 将json字符串反序列化为dict类型
config = Config(json.loads(config_str))
# override config with environment variables.
# Some online deployment platforms (e.g. Railway) deploy project from github directly. So you shouldn't put your secrets like api key in a config file, instead use environment variables to override the default config.
for name, value in os.environ.items():
name = name.lower()
if name in available_setting:
logger.info("[INIT] override config by environ args: {}={}".format(name, value))
try:
config[name] = eval(value)
except:
if value == "false":
config[name] = False
elif value == "true":
config[name] = True
else:
config[name] = value
if config.get("debug", False):
logger.setLevel(logging.DEBUG)
logger.debug("[INIT] set log level to DEBUG")
logger.info("[INIT] load config: {}".format(config))
config.load_user_datas()
def get_root():
return os.path.dirname(os.path.abspath(__file__))
def read_file(path):
with open(path, mode="r", encoding="utf-8") as f:
return f.read()
def conf():
return config
def get_appdata_dir():
data_path = os.path.join(get_root(), conf().get("appdata_dir", ""))
if not os.path.exists(data_path):
logger.info("[INIT] data path not exists, create it: {}".format(data_path))
os.makedirs(data_path)
return data_path
def subscribe_msg():
trigger_prefix = conf().get("single_chat_prefix", [""])[0]
msg = conf().get("subscribe_msg", "")
return msg.format(trigger_prefix=trigger_prefix)
# global plugin config
plugin_config = {}
def write_plugin_config(pconf: dict):
"""
写入插件全局配置
:param pconf: 全量插件配置
"""
global plugin_config
for k in pconf:
plugin_config[k.lower()] = pconf[k]
def pconf(plugin_name: str) -> dict:
"""
根据插件名称获取配置
:param plugin_name: 插件名称
:return: 该插件的配置项
"""
return plugin_config.get(plugin_name.lower())
# 全局配置,用于存放全局生效的状态
global_config = {
"admin_users": []
}
修改完后,将记事本的内容,复制到下图位置:
左侧菜单Docker-项目模板-添加-添加compose模板,把内容贴到4处,最后点击添加
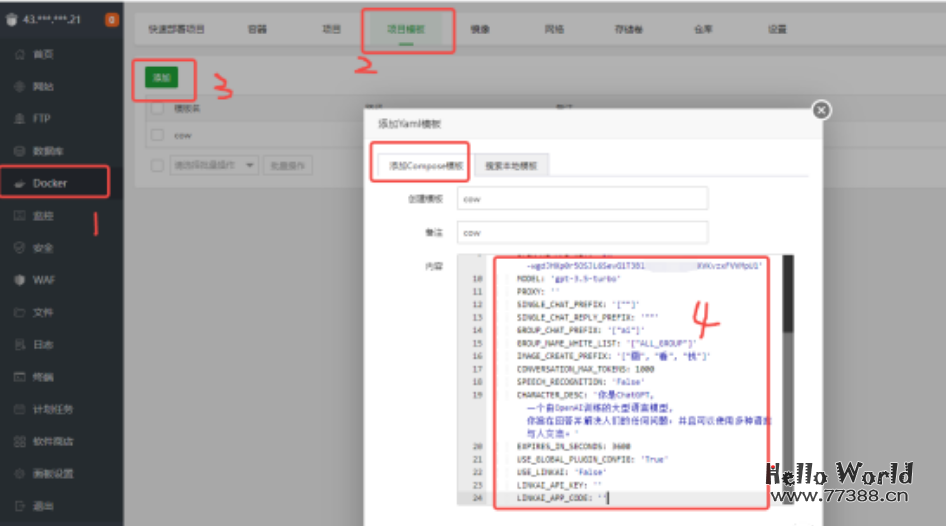
添加compose项目
改完之后,我们打开顶部菜单 项目-添加Compose项目-创建-添加之前创建的模板
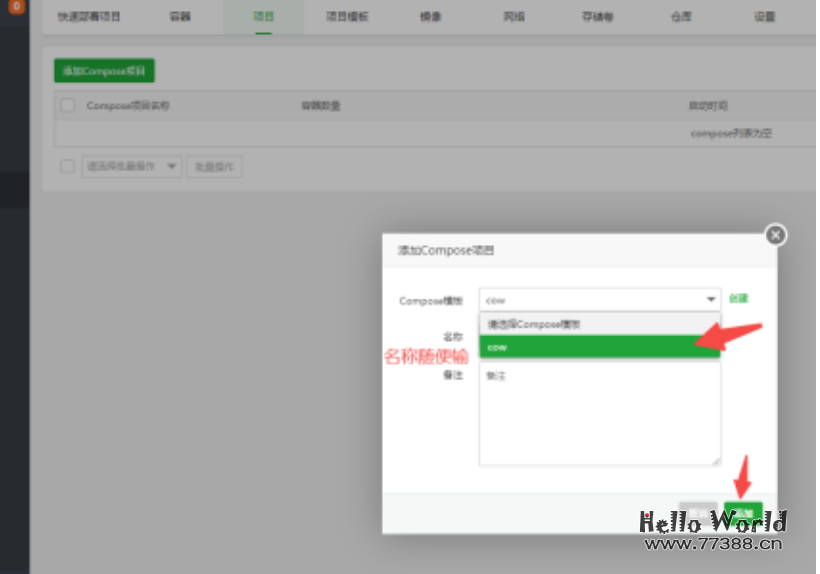
等待约2分钟:
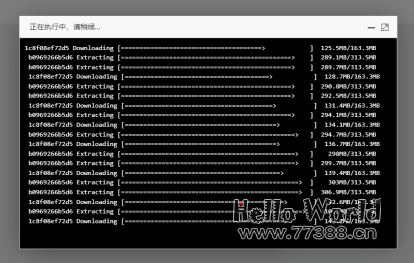
等待弹框自动消失,就是安装完成了
此时点击容器,容器里面已经有一条正在启动的容器记录,点击日志我们可以看到二维码
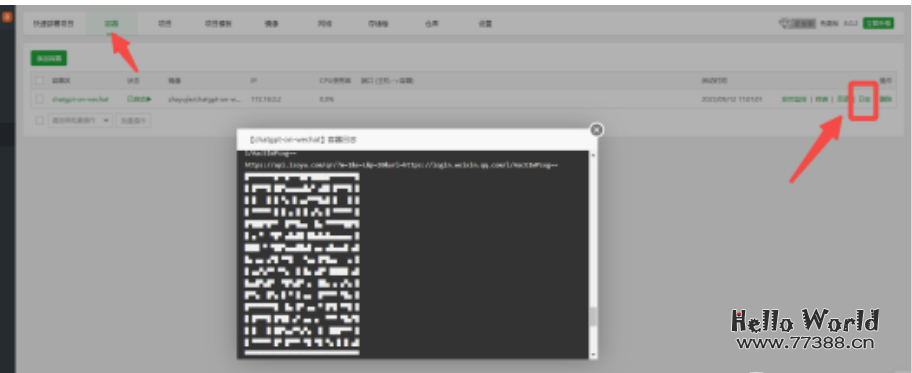
此时拿出你需要做机器人的微信号,扫这个码,此时就已经大功告成了!你可以私聊你的微信机器人,也可以拉入群里做测试。
注意:此二维码可能已经变形,请尝试将手机倾斜角度,可以仰拍,俯拍的形式去扫码就可以成功。
微信机器人项目所需要的源码下载地址:
方案一的部署教程已经就此结束了,方案二的教程,我们明天再写,祝大家玩的愉快!
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


