



引言
大型语言模型资源消耗惊人,10B以内的参数还能够一够,再大就超出范围了(个人想法)。今天给大家分享这篇文章与模型训练相关,基于pytorch,「应用混合精度降低模型训练成本,提高模型训练速度,并且只需一行代码即可实现精度切换」。研究了生成式AI模型Lit-LLaMA的推理速度,该方法可提高30%的性能,降低1倍内存。
32位Float介绍
在GPU上训练深度神经网络时,我们通常使用低于最大精度的精度,即32位浮点运算(事实上,PyTorch 默认使用 32 位浮点数)。
相反,在传统的科学计算中,我们通常使用 64 位浮点数。通常,更多的位数对应于更高的精度,这降低了计算过程中错误累积的机会。因此,64 位浮点数(也称为双精度)长期以来一直是科学计算的标准,因为它们能够以更高的精度表示范围广泛的数字。
然而,在深度学习中,使用 64 位浮点运算被认为是不必要的并且计算量大,因为 64 位运算通常成本更高,而且 GPU 硬件也没有针对 64 位精度进行优化。因此,32 位浮点运算(也称为单精度)已成为在 GPU 上训练深度神经网络的标准。
在浮点数的上下文中,“位”是指用于表示计算机内存中数字的二进制数字。用于表示数字的位数越多,精度越高,可以表示的数值范围也越大。在浮点表示法中,数字存储在三部分的组合中:符号、指数和有效数字(或尾数)。如下图所示: 在浮点数中,值表示为尾数、底数的指数和符号的乘积。有效数字与小数点后的数字相关但不等同。如果您对确切的公式感兴趣(如下图所示),我推荐维基百科上的优秀部分。但是,为方便起见,我们可以将有效数字视为“分数”或“分数值”。
在浮点数中,值表示为尾数、底数的指数和符号的乘积。有效数字与小数点后的数字相关但不等同。如果您对确切的公式感兴趣(如下图所示),我推荐维基百科上的优秀部分。但是,为方便起见,我们可以将有效数字视为“分数”或“分数值”。 因此,回到使用较低精度背后的动机,在 GPU 上训练深度神经网络时,32 位浮点运算优于 64 位运算的主要原因主要有两个:
因此,回到使用较低精度背后的动机,在 GPU 上训练深度神经网络时,32 位浮点运算优于 64 位运算的主要原因主要有两个:
「减少内存占用」。使用 32 位浮点数的主要优点之一是与 64 位浮点数相比,它们需要的内存减少一半。这允许更有效地使用 GPU 内存,从而能够训练更大的模型(和更大的批量大小)。
「增加计算和速度」。由于 32 位浮点运算需要更少的内存,因此 GPU 可以更快地处理它们,从而缩短训练时间。这种加速在深度学习中至关重要,因为在深度学习中训练复杂的模型可能需要几天甚至几周的时间。
从fp32到fp16
前面讨论了32位浮点数的好处,这里更近一步。最近,混合精度训练成为一种常见的训练方案,我们使用的16位精度进行浮点计算,通常称为“半”精度。如下图所示,float16的指数少了3位,小数值少了13位。 但在讨论混合精度训练背后的机制之前,下面非常直观的展示了不同位精度级别之间的差异。考虑PyTorch中的以下代码示例:
但在讨论混合精度训练背后的机制之前,下面非常直观的展示了不同位精度级别之间的差异。考虑PyTorch中的以下代码示例:

 上面的代码示例表明,精度越低,我们在小数点后看到的准确数字就越少。深度学习模型通常对较低精度的算法具有鲁棒性。在大多数情况下相比64位浮点数,使用32位浮点数所导致的精度的轻微降低并不会显著影响模型的预测性能,因此大部分模型都是基于32位浮点进行训练。然而,当我们降低到16位精度时,事情就变得棘手了。您可能会注意到,由于不精确、数值溢出或下溢,损失可能变得不稳定或不收敛。上溢和下溢是指某些数字超出精度格式可以处理的范围的问题,例如,如下所示:
上面的代码示例表明,精度越低,我们在小数点后看到的准确数字就越少。深度学习模型通常对较低精度的算法具有鲁棒性。在大多数情况下相比64位浮点数,使用32位浮点数所导致的精度的轻微降低并不会显著影响模型的预测性能,因此大部分模型都是基于32位浮点进行训练。然而,当我们降低到16位精度时,事情就变得棘手了。您可能会注意到,由于不精确、数值溢出或下溢,损失可能变得不稳定或不收敛。上溢和下溢是指某些数字超出精度格式可以处理的范围的问题,例如,如下所示:
 顺便说一x下,虽然上面的代码片段展示了一些关于不同精度类型的示例,但也可以通过 torch.finfo 直接访问数值属性,如下所示:
顺便说一x下,虽然上面的代码片段展示了一些关于不同精度类型的示例,但也可以通过 torch.finfo 直接访问数值属性,如下所示: 上面的代码显示最大的 float32 数字是340,282,000,000,000,000,000,000,000,000,000,000,000(通过 max);例如,float16数字不能超过值65,504。
上面的代码显示最大的 float32 数字是340,282,000,000,000,000,000,000,000,000,000,000,000(通过 max);例如,float16数字不能超过值65,504。
因此,在本节中,我们鼓励在现代深度学习中使用“混合精度”训练而不是16位精度训练。但是这种混合精度训练是如何工作的呢?为什么它被称为“混合”精度训练而不只是16位精度训练?接下来将继续介绍。
混合精度训练
所谓混合精度训练并不是“低”精度训练,它不会将所有参数和操作都转换为16位浮点数,而是在训练期间在32位和 16 位操作之间切换,因此称为“混合”精度。如下图所示,混合精度训练涉及将权重转换为低精度(FP16)以加快计算速度,计算梯度,将梯度转换回高精度(FP32)以实现数值稳定性,并使用缩放后的原始权重进行梯度更新。 这种方法可以进行有效的训练,同时保持神经网络的准确性和稳定性。更详细地,步骤如下:
这种方法可以进行有效的训练,同时保持神经网络的准确性和稳定性。更详细地,步骤如下:
1、将权重转换为 FP16:在此步骤中,将最初为 FP32 格式的神经网络权重(或参数)转换为精度较低的 FP16 格式。这减少了内存占用并允许更快的计算,因为 FP16 操作需要更少的内存并且可以由硬件更快地处理。
2、计算梯度:神经网络的前向和后向传递使用较低精度的 FP16 权重执行。这一步计算损失函数相对于网络权重的梯度(偏导数),用于在优化过程中更新权重。
3、将梯度转换为 FP32:计算 FP16 中的梯度后,它们将转换回更高精度的 FP32 格式。这种转换对于保持数值稳定性和避免使用低精度算法时可能发生的梯度消失或爆炸等问题至关重要。
4、乘以学习率并更新权重:现在在 FP32 格式中,梯度乘以学习率(确定优化期间步长的标量值)。
5、然后使用第 4 步的产品更新原始 FP32 神经网络权重。学习率有助于控制优化过程的收敛,对于实现良好的性能至关重要。
上面的过程看起来很复杂,但实际上,实现起来还是很简单的。「在下一节中,我们将看到如何通过仅更改一行代码来使用混合精度训练来微调LLM」。
混合精度训练代码示例
使用PyTorch的autocast上下文管理器实现混合精度训练并不复杂。此外,借助PyTorch的开源Fabric库,可以更轻松地在常规训练和混合精度训练之间切换,并且只需要更改一行代码。
首先,来看一下我们针对监督分类任务(此处:用于对电影评论的情绪进行分类的 DistilBERT)在运行时、预测准确性和内存要求方面进行微调的编码器LLM。特别是将微调Transformer的所有层,稍后,我们还将看到「不同精度级别的选择如何影响像LLaMA这样的大型语言模型」。
基准模型微调
以float32位精度以常规方式微调DistilBERT模型的代码开始,下面是PyTorch中的默认设置,全部代码可访问:
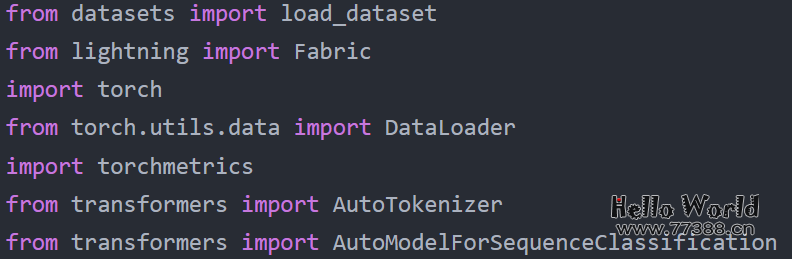
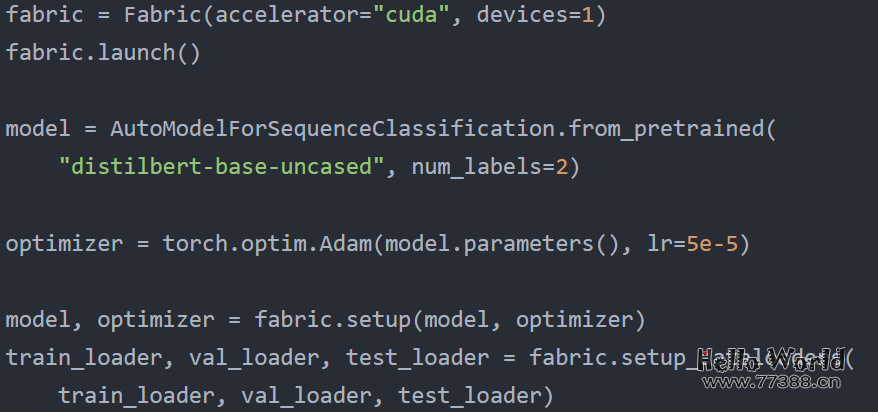
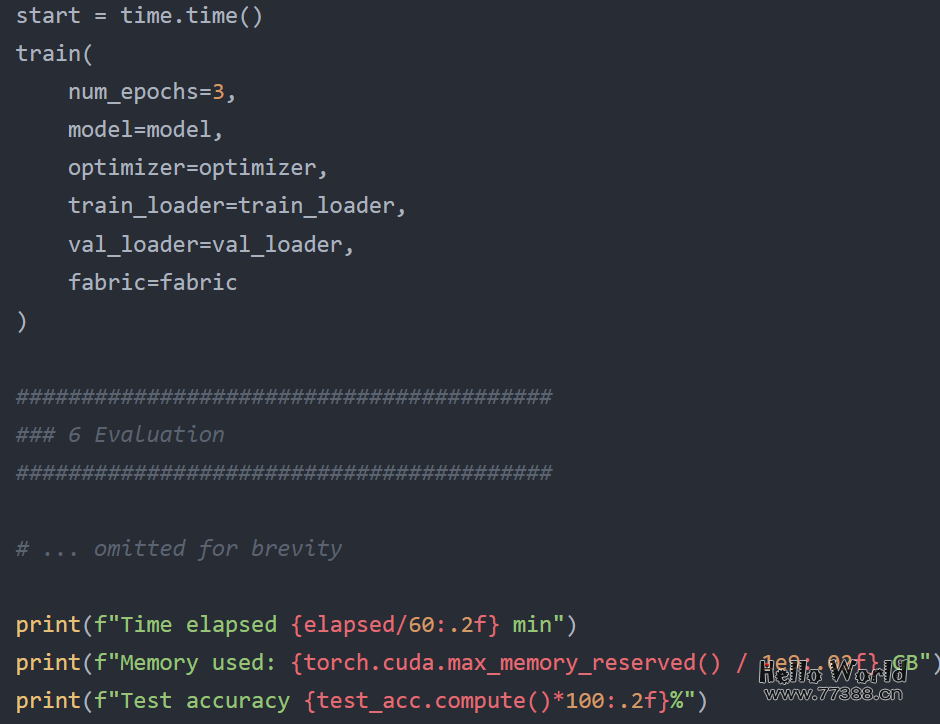 在单个 A100 GPU 上训练的结果如下:
在单个 A100 GPU 上训练的结果如下: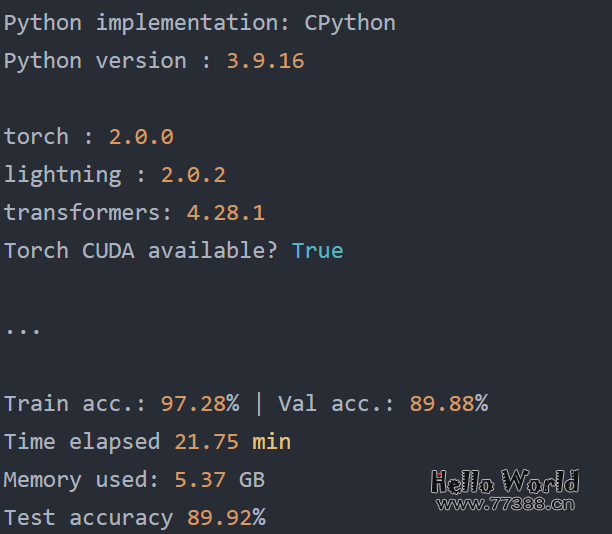 现在,将其与float16混合精度训练进行比较,我们只需更改一行代码如下图所示:
现在,将其与float16混合精度训练进行比较,我们只需更改一行代码如下图所示:
 实验结果如下所示:
实验结果如下所示: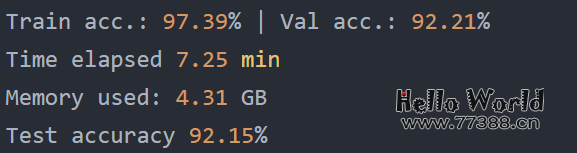 在上面,我们可以看到所需的内存减少了,这可能是因为以 16 位精度执行矩阵乘法。此外,训练速度提高了大约 3 倍,这是巨大的。「一个意想不到的结果是预测准确度也提高了。一个可能的解释是,这是由于使用较低精度的正则化效果」。较低的精度可能会在训练过程中引入一定程度的噪声,这可以帮助模型更好地泛化并减少过度拟合,从而可能导致验证集和测试集的准确性更高。出于好奇,我们还将通过以下方式添加常规(非混合)float16训练的结果:
在上面,我们可以看到所需的内存减少了,这可能是因为以 16 位精度执行矩阵乘法。此外,训练速度提高了大约 3 倍,这是巨大的。「一个意想不到的结果是预测准确度也提高了。一个可能的解释是,这是由于使用较低精度的正则化效果」。较低的精度可能会在训练过程中引入一定程度的噪声,这可以帮助模型更好地泛化并减少过度拟合,从而可能导致验证集和测试集的准确性更高。出于好奇,我们还将通过以下方式添加常规(非混合)float16训练的结果: (请注意,这目前需要通过 pip install git+https://github.com/Lightning-AI/lightning@master 从最新的开发人员分支安装 Lightning。) 不幸的是,常规的float16训练会导致损失不收敛,因此,准确度等于对该数据集的随机预测 (50%)。
(请注意,这目前需要通过 pip install git+https://github.com/Lightning-AI/lightning@master 从最新的开发人员分支安装 Lightning。) 不幸的是,常规的float16训练会导致损失不收敛,因此,准确度等于对该数据集的随机预测 (50%)。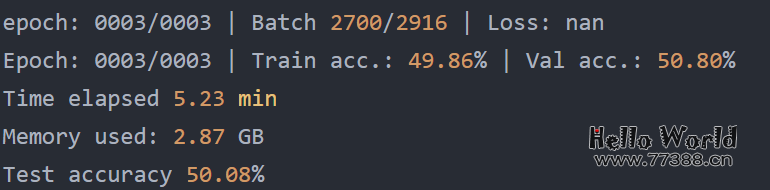 上面的结果总结在下表中:
上面的结果总结在下表中: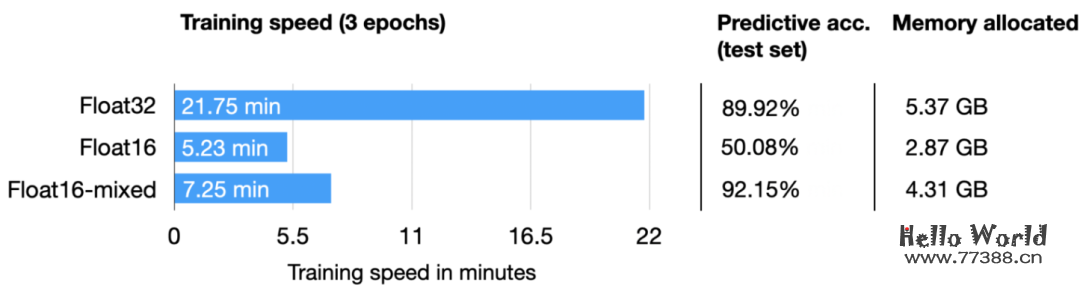 正如我们所见,float16 混合精度几乎与纯float16精度训练(这里存在数值问题)一样快,并且也优于float32预测性能,这可能是由于上面讨论的正则化效果。
正如我们所见,float16 混合精度几乎与纯float16精度训练(这里存在数值问题)一样快,并且也优于float32预测性能,这可能是由于上面讨论的正则化效果。
Tensor Core与矩阵乘法精度
顺便说一下,如果您在支持Tensor Core的GPU上运行之前的代码,您可能已经在终端中通过 PyTorch 看到以下信息: 因此,默认情况下,PyTorch 使用“highest”精度进行矩阵乘法。但如果我们想以更高的精度来换取性能(如此处的 PyTorch 文档中所述),您还可以设置:
因此,默认情况下,PyTorch 使用“highest”精度进行矩阵乘法。但如果我们想以更高的精度来换取性能(如此处的 PyTorch 文档中所述),您还可以设置:
 上面的设置将使用 bfloat16 数据类型进行矩阵乘法,这是float16的一种特殊类型——下一节将详细介绍 bfloat16 类型。因此,换句话说,如果您的GPU支持Tensor Core,则使用torch.set_float32_matmul_precision("high"/"medium") 将隐式启用混合精度训练(通过矩阵乘法)。这对结果有何影响?我们来看一下:
上面的设置将使用 bfloat16 数据类型进行矩阵乘法,这是float16的一种特殊类型——下一节将详细介绍 bfloat16 类型。因此,换句话说,如果您的GPU支持Tensor Core,则使用torch.set_float32_matmul_precision("high"/"medium") 将隐式启用混合精度训练(通过矩阵乘法)。这对结果有何影响?我们来看一下: 正如我们在上面看到的,对于 float32 精度,降低矩阵乘法精度具有显着效果,将计算性能提高 2.5 倍并将内存需求减半。此外,预测准确性增加,可能是由于前面提到的较低精度的正则化效应。事实上,使用矩阵乘法精度较低的float32训练在性能上几乎等同于float16混合精度训练。此外,为 float16 启用较低的矩阵乘法精度不会改善结果,因为 float16 混合精度训练已经使用 float16 精度进行矩阵乘法。
正如我们在上面看到的,对于 float32 精度,降低矩阵乘法精度具有显着效果,将计算性能提高 2.5 倍并将内存需求减半。此外,预测准确性增加,可能是由于前面提到的较低精度的正则化效应。事实上,使用矩阵乘法精度较低的float32训练在性能上几乎等同于float16混合精度训练。此外,为 float16 启用较低的矩阵乘法精度不会改善结果,因为 float16 混合精度训练已经使用 float16 精度进行矩阵乘法。
Bfloat16
另一种浮点格式最近流行起来,即 Brain Floating Point (bfloat16)。Google 为机器学习和深度学习应用开发了这种格式,特别是在他们的张量处理单元(TPU) 中。与传统的float16格式相比,Bfloat16 以降低精度为代价扩展了动态范围。 扩展的动态范围有助于bfloat16表示非常大和非常小的数字,使其更适合可能遇到各种值的深度学习应用程序。但是,较低的精度可能会影响某些计算的准确性或在某些情况下导致舍入误差。但在大多数深度学习应用程序中,这种精度降低对建模性能的影响微乎其微。虽然 bfloat16 最初是为 TPU 开发的,但这种格式现在也得到了多个 NVIDIA GPU 的支持,首先是 A100 Tensor Core GPU,它们是 NVIDIA Ampere 架构的一部分。您可以通过以下代码检查您的 GPU 是否支持 bfloat16:
扩展的动态范围有助于bfloat16表示非常大和非常小的数字,使其更适合可能遇到各种值的深度学习应用程序。但是,较低的精度可能会影响某些计算的准确性或在某些情况下导致舍入误差。但在大多数深度学习应用程序中,这种精度降低对建模性能的影响微乎其微。虽然 bfloat16 最初是为 TPU 开发的,但这种格式现在也得到了多个 NVIDIA GPU 的支持,首先是 A100 Tensor Core GPU,它们是 NVIDIA Ampere 架构的一部分。您可以通过以下代码检查您的 GPU 是否支持 bfloat16: bfloat16能否使我们进一步受益?为了回答这个问题,让我们通过更改一行代码来添加运行先前DistilBERT代码的bfloat16结果:
bfloat16能否使我们进一步受益?为了回答这个问题,让我们通过更改一行代码来添加运行先前DistilBERT代码的bfloat16结果:
 为了完整起见,我还添加了float64运行的结果。我们也试了常规的(不是混合精度的)bfloat16 训练:
为了完整起见,我还添加了float64运行的结果。我们也试了常规的(不是混合精度的)bfloat16 训练: 有趣的是,float64 在这里实现了比 float32 更高的精度,这与我们之前关于较低精度对该模型具有正则化效果的论点相矛盾。然而,有趣的是,Bfloat16 混合精度训练(92.61%)在预测性能方面与 Float16(92.15%)混合精度训练相比,结果略有提高;不过,它使用了更多的内存。请注意,我们不能在比较中包括常规 Float16 (50%) 训练,因为它由于低精度而无法正确训练。总而言之,混合float16精度和混合bfloat16精度训练在这里表现得比较相似,这并不意外。
有趣的是,float64 在这里实现了比 float32 更高的精度,这与我们之前关于较低精度对该模型具有正则化效果的论点相矛盾。然而,有趣的是,Bfloat16 混合精度训练(92.61%)在预测性能方面与 Float16(92.15%)混合精度训练相比,结果略有提高;不过,它使用了更多的内存。请注意,我们不能在比较中包括常规 Float16 (50%) 训练,因为它由于低精度而无法正确训练。总而言之,混合float16精度和混合bfloat16精度训练在这里表现得比较相似,这并不意外。
混合精度与LLaMA
混合精度训练可以扩展到深度学习模型中的推理,以提高效率、减少内存占用并加速计算。但是,我们必须记住,在推理过程中应用较低的精度可能会由于数值精度降低而导致模型精度略有下降。然而,在许多深度学习应用程序中,对准确性的影响是最小的,并且是减少内存使用和加快计算的好处的可接受权衡。
事实上,上面的混合精度微调代码在计算训练、验证和测试集精度时,已经使用16位精度通过Fabric 设置进行推理。由于DistilBERT是一个相对较小的模型,因此推理速度仅占总运行时间的一小部分。接下来我们看一下对大模型的影响,这里选择了Meta的LLaMA模型:
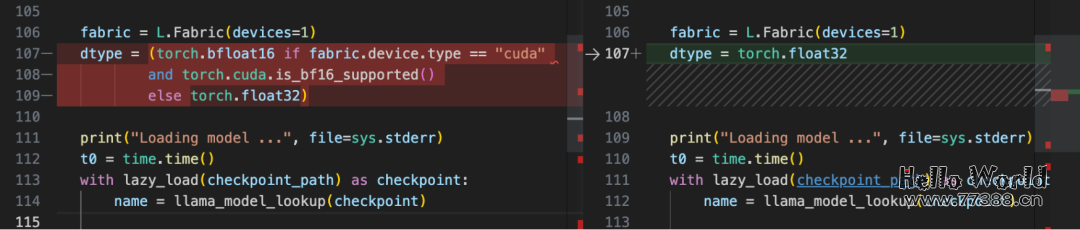 我们可以看到模型现在使用了两倍的内存,模型现在慢了30%。
我们可以看到模型现在使用了两倍的内存,模型现在慢了30%。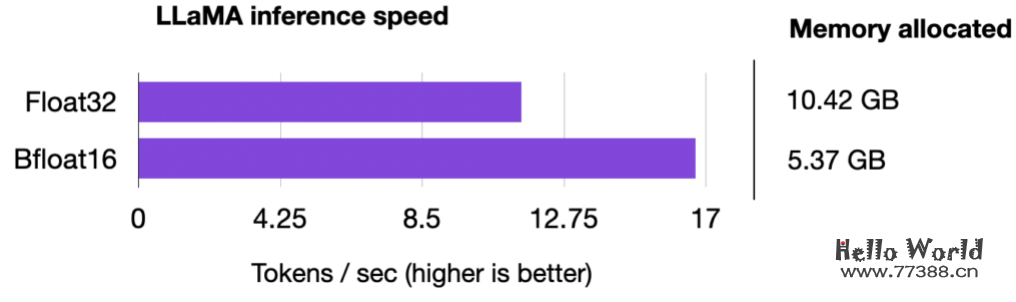
结论
在本文中,我们了解了如何使用16位精度技术将LLM分类器的训练速度显着提高3倍。此外,我们还能够将内存消耗减半!此外,我们研究了生成式AI模型的推理速度,并且能够将性能提高 30%,同时将内存效率提高一倍。因此,如果您使用支持混合精度训练的GPU,混合精度训练工具值得拥有。
本站资源部分来自网友投稿,如有侵犯你的权益请联系管理员或给邮箱发送邮件PubwinSoft@foxmail.com 我们会第一时间进行审核删除。
站内资源为网友个人学习或测试研究使用,未经原版权作者许可,禁止用于任何商业途径!请在下载24小时内删除!
如果遇到评论可下载的文章,评论后刷新页面点击“对应的蓝字按钮”即可跳转到下载页面!
本站资源少部分采用7z压缩,为防止有人压缩软件不支持7z格式,7z解压,建议下载7-zip,zip、rar解压,建议下载WinRAR。
温馨提示:本站部分付费下载资源收取的费用为资源收集整理费用,并非资源费用,不对下载的资源提供任何技术支持及售后服务。


